So we have created an (AMI) with installed. In this post I will examine the sort of single core performance you can expect and much this is likely to cost compared to other compute options you might have.
Benchmark
To test the different types of instances you can deploy our GROMACS image on, we need a benchmark system to test. For this I’ve chosen a peptide MFS transporter in a simple POPC lipid bilayer solvated by water. This is very similar to the simulations found in . Or to put it another way: 78,000 atoms in a cube, most of which are water, some belong to lipids and the rest, protein. It is fully atomistic and is described using the CHARMM27 forcefield.
Computing Resources Tested
I tried to use a range of compute resources to provide a good comparison for AWS. First, and most obviously, I used my workstation on my desk, which is a which has 12 Intel Xeon cores. In our department we also have a small compute cluster, each node of which has 16 cores. Some of these nodes also have a K20 GPU. Then I also have access to run by the University. Unfortunately, since the division I am in has decided not to contribute to its running, I have to pay for any significant usage.
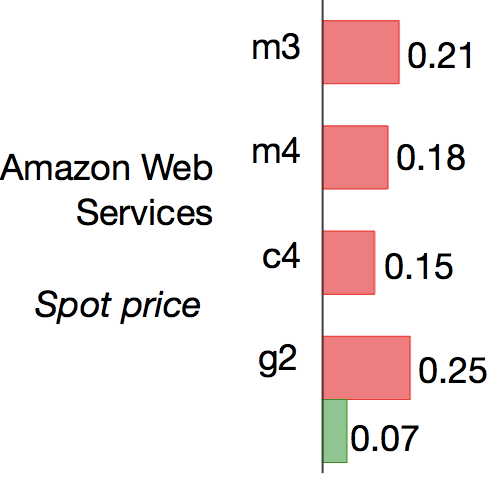
Rather than test all the available on EC2, I tested an example from each of the current (m4) and older generation (m3) of non-burstable general purpose instances. I also tested an example from the latest generation of compute instances (c4) and finally the smaller instance from the GPU instances (g2).
Performance
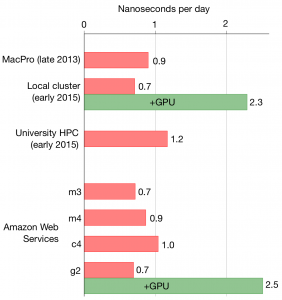
The performance, in nanoseconds per day for a single compute core, is shown on the left (bigger is better).
One worry about AWS EC2 is that for a highly-optimised compute code, like GROMACS, performance might suffer due to the layers of virtualisation, but, as you can see, even the current generation of general purpose instances is as fast as my MacPro workstation. The fastest machine, perhaps unsurprisingly, is the new University compute cluster. On AWS, the compute c2 class is faster than the current general purpose m4 class, which in turn is faster than the older generation general purpose m3 class. Finally, as you might expect, using a GPU boosts performance by slightly more than 3x.
Cost
 I’m going to do a “real�? comparison. So if I buy a compute cluster and keep it in the department I only have to pay the purchase cost but none of the running costs. So I’m assuming the workstation is £2,500 and a single 16-core node is £4,000 and both of these have a five year lifetime. Alternatively I can use the university’s high performance computing clusters at 2p per core hour. This obviously is unfair on the university facility as this does include operational costs, like electricity, staff etc, and you can see that reflected in the difference in costs.
I’m going to do a “real�? comparison. So if I buy a compute cluster and keep it in the department I only have to pay the purchase cost but none of the running costs. So I’m assuming the workstation is £2,500 and a single 16-core node is £4,000 and both of these have a five year lifetime. Alternatively I can use the university’s high performance computing clusters at 2p per core hour. This obviously is unfair on the university facility as this does include operational costs, like electricity, staff etc, and you can see that reflected in the difference in costs.
So AWS EC2 more or less expensive? This hinges on whether you use it in the standard “on demand�? manner or instead get access through bidding via the market. The later is significantly cheaper but you only have access whilst your bid price is above the current “spot price�? and so you can’t guarantee access and your simulations have to be able to cope with restarts. Since the spot price varies with time, I took the average of two prices at different times on Wed 13 Jan 2016.
As you can see AWS is more expensive per core hour if you use it “on demand�?, but is cheaper than the university facility if you are willing to surf the market. Really, though we should be considering the cost efficiency i.e. the cost per nanosecond as this also takes into account the performance.
Cost efficiency

When we do this an interesting picture emerges: using AWS EC2 via bidding on the market is cheaper than using the university facility and can be as cheap as buying your own hardware even if you don’t have to pay the running costs. Furthermore, as you’d expect, using a GPU decreases cost and so should be a no-brainer for GROMACS.
Of course, this assumes lots of people don’t start using the EC2 market, thereby driving the spot price up…